This is just to spread a small life-hack I came up with for furry conventions.
I’ll probably post a couple more of those small life-hacks next couple days, if
things go well. (Coming back from Anthrocon with some sorta
con-crud so I’m a little dead. Probably kissed too many boys.)
When you’re at a con (or an event of any sort), in your messenger app (mine is
Telegram), make a folder with everyone you know at that event, or any event
chats you wanna follow.
This is how that looked for me at Anthrocon:
Then, when you’re in between things and are looking for people to join/stuff to
do, just go through that folder.
Having all the people in one folder makes it way easier to remember “oh I wanted
to meet person X”, or to just shower everyone in a “hi I’m free wanna hang out”
message.
(And in Telegram, you can also put that folder to the top of the chat group
list, which makes sense if you’re at a con - then you probably want to mostly
chat with other people at the con anyway.)
In May 2022, I started working at OpenAI as a resident on RL team, and
eventually I got hired as full-time. As of today, I’m still at OpenAI, and I’m
working on some ChatGPT related stuff and try to make progress on scalable
alignment. I want to make a brief write-up of how this happened, because
sometimes people ask about it and it might be helpful to other people in a
similar situation.
TL;DR, this is the last couple steps:
Repeat a couple of times:
Make a list of stuff that’s relevant to ML I don’t yet grok.
Find resources to grok it. Some examples:
I consumed all the TensorFlow tutorials that don’t go to too niche topics (though today I’d do PyTorch).
And of course made tons of Anki cards.
Contact me if you want some of them.
I’ve always been good with math and computers. (I started out as a more general
hacker, including electronics etc., but eventually specialized.)
I did some competitive programming, high school programming seminars, olympiads
etc. I got to district level rounds, and my top achievements were being ~#20-30
in competitive “algorithmic programming” (which is part of math olympiad in
Czech Republic), and being #1 in competitive “practical programming” (which is
more “write a program for task X” rather than “solve this theoretical problem”.
Bachelor’s
I took a wide approach to consume all the knowledge at uni. Since high school
I’ve been freelancing, writing up small programs/websites. I leveraged that into
a series of internships - first Represent.com in Prague (via Juraj
Masar, who
was in roughly the same uni year), then half a year for Google in Paris, then
Dropbox.
When in USA on the Dropbox internship, I got an offer from
Cruise and Coinbase
via Triplebyte. I also did full-time interviews with
Google and got an offer.
It turned out I was not mentally/spiritually ready for making the move to USA.
I continued on with a master’s, keeping the Google offer in my back pocket.
Master’s
It was easy to do all the required courses but I ended up getting stuck on the
last master’s requirement - the thesis.
I tried to work on knowledge base completion with
Pasky as my supervisor (who ended up (co-?)founding
Rossum where he’s currently CTO).
This was roughly at the time when the seminal Transformers paper
Attention is All You Need, maybe +/- half
a year or so.
I got involved in the rationality community in Prague and the EA community
that eventually sprouted out of it. I co-founded the
Czech EA association.
I wanted to do an open-source re-implementation of Google’s Knowledge
Vault.
It’s basically where you take Google’s Knowledge Graph, you mix in a bunch of
unstructured data like Wikipedia or such, and based on that and some neural
networks trained on the graph, you make a bigger graph, where you suggest “I think there’s relation R between entities X and Y, with probability P=0.97”.
Coming from Google, I assumed this would be pretty easy - you’d plug in standard
building blocks for MapReduce-type pipelines, and out would come a model.
I was trying to immediately jump to a larger scale project - completing the
DBpedia knowledge graph with Wikipedia text.
Things turned out way harder than I expected. I tried to use Bazel to build
Hadoop stuff to chew up Wikipedia articles, and HBase (Hadoop’s BigTable
basically) to store Wikipedia articles. I ran into tons of stupid problems -
like “oops, library X which I need and library Y which I need depend on versions
of library Z which are incompatible, so you gotta split these 2 functions into
separate binaries”. Or “oops maximum runtime on this cluster is 24 hours lol”.
The iteration time was horrible.
Rai sticker, by
Ketzel99. It doesn’t
have a name but I think “computers were a mistake” would fit.
Today I’d probably try to approach this with less hubris, and try to start from
smaller pieces, so that I’d have a fast iteration turn-out.
And also, I’d just … drop all the manual NLP and throw a Transformer at the
problem. But oh well, you live and learn.
I was working in the same office as a group of CUNI folks who
ended up winning an Amazon tournament for writing a chit-chat agent, but I
wasn’t working in their ecosystem - the knowledge base completion I was doing
was basically playing on my own little field.
On top of that, I experienced a mental health crisis, and I felt like neither me
nor anyone else will ever care about what I do in the thesis. I became depressed
and to this day feel like I haven’t quite 100% recovered. But I think that’s
more “pre-existing problems came to the surface and I can no longer ignore
them”, rather than “at this point I started having problems”.
But I always felt sadness/envy/impostor syndrome seeing that I wasn’t one of the
national-best-level people in the theoretical stuff.
In between the work being hard and frustrating and disconnected, and the mental
health crisis, I dropped my master’s thesis, but stayed formally enrolled as a
student.
Google ended up getting tired of me trying to postpone the offer for longer. I
accepted it, didn’t get a H1b, and ended up getting an offer in Google
Switzerland.
Google
At Google, the first team I worked on was doing some stuff which cared about
metrics and was downstream of NLP, but there wasn’t really organizational
alignment that AI mattered. There were some applications of AI in isolated
places, but the problems my team was responsible for were much more shaped like
software engineering - building pipelines, services, etc. - than research
engineering.
I was sorta hoping to finish my master’s thesis, but of course, didn’t have time
to do it. I kept paying my uni to extend my studies, but eventually the clock
ran out. And so I did finish all the courses for a master’s, but never actually
got it, because I didn’t get around to doing the thesis.
Within Google, my original hope was that I’d try to position myself into a team
that would be AI or AI-adjacent, do researchy stuff, eventually position myself
to work on AI safety. But it ended up very hard trying to switch myself from
“software engineer working in team X doing software engineer things” into
“research engineer in ML”. I didn’t have any proven experience saying “I can do
ML” - all I had was “hey I did all this stuff in uni”. But whenever I tried to
apply for an internal transfer, somehow it didn’t end up working out. I think
there must have been very hard competition. And getting rejections was always an
ow.
My self-confidence suffered and I started feeling like I’m “not smart enough” or
“not good enough to do this”. I envied people I knew who were working with ML.
Eventually I ended up saving up a bunch of money, including being lucky with
crypto. I though about it a bunch, and decided that I just felt dissatisfied
with the work at Google. It wasn’t evolving me in the direction of working in
AI. I was good at my work, but I wasn’t getting the skills I wanted to get.
FIRE mode
Since uni I was following the “financial independence / early retirement” (FIRE)
philosophy. See places like
/r/financialindependence for info
on that. With the money I saved my simulations showed I had a maybe like 80% of
being able to stay in Switzerland, on my level of spending, basically
indefinitely.
So I started just chilling in Switzerland, basically trying out “what early
retirement would be like”.
I played a lot of Civilization 6 and Civilization 5. I didn’t really feel better
than when I was working - maybe even worse. When you’re at work, you
automatically get a bit of socializing. When you’re not, it’s actually up to
your own initiative to meet people, and that was sorta hard in Switzerland.
Chilling and learning ML
I never thought of FIRE as “I’d retire and then I just chill on the beach
sipping piña coladas forever”. I wanted to find a mix of seeing friends, having
fun, and doing stuff that I felt like it mattered.
When I did the EA stuff in Czech Republic (like organizing the first
EAGxPrague), it felt like it mattered. Work on AI alignment would matter - if I
could manage to do it. Failing that, I thought maybe I’d find work someplace
where I liked the mission and product. I contributed to some open-source, like
Anki and Athens Research.
I’ve decided to try to put some more effort re-learning all the stuff I learned
about AI in uni, except this time I wanted to actually grok it, where you
could wake me up at 2 AM 5 years from now and I’d still be able to explain to
you how it works. I went over old materials and re-learned them, making Anki
cards, and started refilling the holes where my knowledge was stuck before
2017-era progress in AI - like deep RL or Transformer language models.
Also a Rai sticker by
Ketzel99.
“Science was a mistake”? Maybe writing was? When reading paper X
that assumes you’ve taken Advanced Xology and did all the background
reading on Y, Z, α, β… sometimes it indeed do be like that.
To repeat the bullet points from the initial TL;DR, this was the procedure:
Repeat a couple of times:
Make a list of stuff that’s relevant to ML I don’t yet grok.
Find resources to grok it. Some examples:
I consumed all the TensorFlow tutorials that don’t go to too niche topics (though today I’d do PyTorch).
And of course made tons of Anki cards.
Contact me if you want some of them.
Nowadays, I’d actually recommend Jacob Hilton’s
Deep Learning curriculum.
It’s based on an OpenAI-internal curriculum for residents and it’s really good
at building up a good background for work at OpenAI.
So, I’ve been slowly taking courses, sometimes experimenting, sometimes reading
papers. Eventually I found the paper Proximal Policy Optimization Algorithms.
Rai “STACK MORE LAYERS” sticker, by
Ketzel99.
This is my life now.
I tried pretty hard to grok it, because it is sorta magic. One day I wanna write
a blog post explaining it. There’s a whole bunch of math involved in proving
that it actually works.
But I’ve been trying to build really deep foundations, really grok all the
stuff involved in doing ML. To the point that theoretically I’d be able to
relay all of this to a Russian babushka, given enough time.
Reading that paper, I found a few small mistakes in exposition.
The first author on that paper is John Schulman.
I sent him an email.
In the background I’ve been on the lookout for some roles. I hoped eventually
I’d be able to take some role where I’d build up a bit of ML experience, and
then I’d be able to take that and leverage it into a role closer to AI safety.
John responded to the email, and invited me to apply to the OpenAI residency.
OpenAI had 2 residency tracks: software engineer and research. Originally I was
scared of applying for research, because of all the self-doubt and impostor
syndrome I was (and still to a degree am) carrying from having failed to write
a master’s thesis.
But John encouraged me to try the research track, maybe believing in myself more
than I did - and I made it through. The research interview was the most nervous
I felt interviewing ever - it was a multi-hour small sized research project
involving tools like Jupyter, NumPy, etc.
And I made it. It was very useful to have all the commands for Pandas, NumPy,
etc. memorized in Anki. But if I had to take the interview again, I’d recommend
myself to spend more time playing around with various algorithms, grokking how
they behave as you change parameters, etc.
I ended up getting accepted both for the OpenAI residency, and an internship at
CHAI. Both of them would have been awesome to work on. Out of these two, I chose
to go with the residency - mostly because I felt that because CHAI was an
academic institution, it would have been harder to grow there post-internship
if I wasn’t a PhD candidate.
Conclusions and recommendations
Here’s stuff I would have done differently and that I’d recommend to people in a
similar position:
Be safe but take risks.
I think I should have been less afraid to leave Google and be without a source
of income for a while. Theoretically I think I could have executed the “take a
year off and do some studying” thing maybe without even going through Google.
Though the Google experience definitely made me a much better engineer.
If you want to work on AI safety, I’d recommend doing something like this (“take
a year off and learn AI”) when you have maybe like 18 months of runway. I had way
more runway than that at the point when I did that.
Community is super important.
I’d recommend myself to try harder to find other people who do things like
read AI papers, do experiments, etc. - like AI meetups, AI safety camp, that
sort of thing.
Local optimizations are also important.
In Switzerland, I was for a while in a loop where I felt depressed that I
wasn’t moving forward toward working in AI, and didn’t have the energy to do
that.
I think one thing which helped a bunch was starting to actually learn German.
Did I want to stay in Switzerland long-term? No, not necessarily. But it did
make me feel way less like an alien. I didn’t immediately broadcast to
everyone “I’m a tourist” whenever I wanted to have a coffee. And I felt like
“hey - I’m achieving a thing!”
I’d generalize this to:
“Tactics mean doing what you can with what you have.”
– Civilization 6 flavor text for Military Tactics tech, originally Saul Alinsky.
Do you really want to do thing [X] but it’s really hard and discouraging and
depressing because all actions towards [X] are not in the range of stuff you
can do now?
Maybe go and take a walk around the block. Wash the dishes. Will it solve [X]?
No, but you’ll make things easier for future-you. Exercise is healthy for the
mind and body. Having a nice orderly environment makes it so that when you
wake up, your first thought isn’t “ugh, all this mess”.
Do what you can with what you have.
Don’t fall victim to impostor syndrome.
If anyone figures out how to solve this one in full generality, let me know :)
I think part of that can be just hanging around people who are nice and
support you. For me, actively joining the furry community has been an
important part of that. I haven’t read Vega’s Opinionated
Guides yet (they’re on the to-read list), but I
think the Community
guide might have useful pointers. The furry community is great and so is the
hacker community. For both of those, I’ve known for a long time that they
exist and I wish I became actively involved way earlier.
I hope maybe this might give another nudge to people who’d like to work on
alignment, or that some of this advice might be useful.
I’m Rai and I’m a furry (specifically, dragon). The last couple years, I’ve been
running a Furry Rationalists Telegram group. It looks like we exist, and not
everyone who should know we exist does yet, so I wanted to just write this to
advertise that this furry+EA/rationality corner exists, and if you’re
furry-adjacent & rationality-adjacent and nice, you’re invited to join us :)
There’s ~50 of us and we’re chill - we have self-improvement, science, and cute
animal GIFs. If you’d like a preview, here’s the guidelines + meta doc.
We’re 18+, but we’re not adult-oriented - we’re 18+ just so that we can talk
about adult stuff if it does come up. If you happen to be <18 and wanna join,
let me know, we might update this.
If you’re reading this a while later, and the link expired, contact me (via
some method on this website), or look us up on
https://www.furry-telegram-groups.net/, a search for “rationality” should find
us.
GNOME has a feature where there’s a system-level setting for whether user
prefers light or dark theme. This got added relatively recently (in GNOME
42). Its intended use is so that apps can automatically adjust to match
the user’s preferences without hacks. Hacks like “read the current GTK theme
and try to figure out whether it’s light or dark based on some heuristic”.
Today I’ve managed to put together one annoying missing piece of personal infra.
I’ve had gnome-terminal sorta-following the setting for a while, and tonight
I’ve made Neovim also do that. To celebrate, I wanted to share how
this works.
GNOME Terminal and Neovim both following system theme
All scripts copied here are in my ducktape repo in
dotfiles/local/bin, where you can copy fork and improve
to your heart’s content. The Neovim part was added in MR #81.
Those are the dependencies:
pip install pynvim absl-py dbus-python
Shared setup
Night Theme Switcher
Install the Night Theme Switcher GNOME extension.
This extension lets you attach scripts to when the theme is changed.
Light/dark scripts
Create a pair of scripts, set_light_theme and set_dark_theme, put them
wherever. Mine are currently in ~/.local/bin.
Point Night Theme Switcher to run those when the theme is changed.
Neovim
In my particular case, I like Solarized colors, which I have
everywhere I can (VSCode, Neovim, gnome-terminal, even this site - as of now).
I use the vim-colors-solarized plugin which adds
both light and dark variants, toggled by set background=light or dark.
init.vim
Open ~/.config/nvim/init.vim and add this hunk somewhere near the top.
It’ll read the current setting from gsettings and update Vim’s background to
match.
" Set color theme to light/dark based on current system preferences.
" Done early to prefer flashing of the wrong theme before this runs.
" Will later be picked up when setting up Solarized colors.
" Called on theme switches by set_light_theme, set_dark_theme scripts.
function! UpdateThemeFromGnome()
if !executable('gsettings')
return
endif
let color_scheme = system('gsettings get org.gnome.desktop.interface color-scheme')
" remove newline character from color_scheme
let color_scheme = substitute(color_scheme, "\n", "", "")
" Remove quote marks
let color_scheme = substitute(color_scheme, "'", "", "g")
if color_scheme == 'prefer-dark'
set background=dark
else
" With disabled night mode, value seems to be to 'default' on my system.
set background=light
endif
endfunction
call UpdateThemeFromGnome()
update_nvim_theme_from_gnome
Create this script somewhere and chmod +x it.
I named it update_nvim_theme_from_gnome.
It’ll use pynvim to connect to running Neovim instances and run the function
we made above to update the background.
#!/usr/bin/python# Updates the theme on all running Neovim instances.import globimport osfrom pynvim import attach# TODO: should probably only try to do this to *my* neovim instancesfordirin glob.glob('/tmp/nvim*'): socket = os.path.join(dir, '0') nvim = attach("socket", path=socket) nvim.command("call UpdateThemeFromGnome()")
Update set_light_theme and set_dark_theme to call it. This will make it so
that when you switch theme, it’ll not just affect new Neovim instances, but also
all currently running ones.
There’s a TODO in there. Exercise for the reader I guess - I don’t particularly
care because I rarely run Neovim as root, but I expect this would crash
and burn if there were Neovim running as any user other than you. Cause it would
probably not let you write into that socket.
GNOME Terminal
I have another script for GNOME Terminal doing something similar.
It assumes that you have a light and dark profile set up. Open GNOME Terminal
preferences and note down the names of the profiles you wanna use in
light/dark configurations
#!/usr/bin/python# Works on gnome-terminal 3.44.0 as of 2022-09-03.# Requirements: absl-py, dbus-pythonfrom typing import Listimport jsonimport reimport subprocessimport astimport dbusfrom xml.etree import ElementTreefrom absl import app, flags, logging_PROFILE = flags.DEFINE_string('profile', None,'Name or UUID of profile to set everywhere')def gsettings_get_profile_uuid_list() -> List[str]: out = subprocess.check_output( ["gsettings", "get", "org.gnome.Terminal.ProfilesList","list"]).decode('utf-8')return ast.literal_eval(out)def gsettings_get_default_profile_uuid() ->str: out = subprocess.check_output( ["gsettings", "get", "org.gnome.Terminal.ProfilesList","default"]).decode('utf-8')return ast.literal_eval(out)def gsettings_set_default_profile_uuid(uuid: str) ->None: out = subprocess.check_output(["gsettings", "set", "org.gnome.Terminal.ProfilesList", "default",f"'{uuid}'" ]).decode('utf-8')assert out ==''def dconf_get_profile_visible_name(uuid: str) ->str:# As of 2022-09-03 (gnome-terminal 3.44.0), somehow the visible-name only# seems to propagate correctly into dconf, not into gsettings...# but the list of profiles (ProfileList) is up in gsettings.# dconf list /org/gnome/terminal/legacy/profiles:/ returns a lot of profiles# which I've deleted a long time back. name = subprocess.check_output(["dconf", "read",f"/org/gnome/terminal/legacy/profiles:/:{uuid}/visible-name" ]).decode('utf-8').strip()return ast.literal_eval(name)def dbus_update_profile_on_all_windows(uuid: str) ->None: bus = dbus.SessionBus() obj = bus.get_object('org.gnome.Terminal', '/org/gnome/Terminal/window') iface = dbus.Interface(obj, 'org.freedesktop.DBus.Introspectable') tree = ElementTree.fromstring(iface.Introspect()) windows = [child.attrib['name'] for child in tree if child.tag =='node'] logging.info("requesting new uuid: %s", uuid)def _get_window_profile_uuid(window_actions_iface):# gnome-terminal source code pointer:# https://gitlab.gnome.org/GNOME/gnome-terminal/-/blob/f85f2a381e5ba9904d00236e46fc72ae31253ff0/src/terminal-window.cc#L402# D-Feet (https://wiki.gnome.org/action/show/Apps/DFeet) is useful for# manual poking. description = window_actions_iface.Describe('profile') profile_uuid = description[2][0]return profile_uuidfor window in windows: window_path =f'/org/gnome/Terminal/window/{window}'# TODO: if there's other windows open - like Gnome Terminal preferences,# About dialog etc. - this will also catch those windows and fail# because they do not have the 'profile' action. obj = bus.get_object('org.gnome.Terminal', window_path) logging.info("talking to: %s", obj) window_actions_iface = dbus.Interface(obj, 'org.gtk.Actions') logging.info("current uuid: %s", _get_window_profile_uuid(window_actions_iface))#res = window_actions_iface.Activate('about', [], []) res = window_actions_iface.SetState(# https://wiki.gnome.org/Projects/GLib/GApplication/DBusAPI#Overview-2# https://gitlab.gnome.org/GNOME/gnome-terminal/-/blob/f85f2a381e5ba9904d00236e46fc72ae31253ff0/src/terminal-window.cc#L2132'profile',# Requested new state# https://gitlab.gnome.org/GNOME/gnome-terminal/-/blob/f85f2a381e5ba9904d00236e46fc72ae31253ff0/src/terminal-window.cc#L1319 uuid,# "Platform data" - `a{sv}` []) logging.info("window_actions_iface.SetState result: %s", res) uuid_after = _get_window_profile_uuid(window_actions_iface) logging.info("new uuid: %s", uuid_after)assert new_uuid == uuid# TODO: this only includes currently active tabs, not background tabs :/def main(_): profile_uuids =set(gsettings_get_profile_uuid_list()) uuid_by_name = {}for uuid in profile_uuids: name = dconf_get_profile_visible_name(uuid) uuid_by_name[name] = uuidif _PROFILE.value in profile_uuids: uuid = _PROFILE.valueelif _PROFILE.value in uuid_by_name: uuid = uuid_by_name[_PROFILE.value]else:raiseException("No such profile (by UUID or name)") gsettings_set_default_profile_uuid(uuid) dbus_update_profile_on_all_windows(uuid)if__name__=='__main__': flags.mark_flag_as_required(_PROFILE.name) app.run(main)
This script expects a profile name or UUID in --profile, and when called,
it’ll update GNOME Terminal’s settings to have that profile be the default.
That will make any new terminal windows/tabs use that profile.
Then it’ll talk to GNOME Terminal over dbus and update the profile
of each window. Unfortunately, this only updates the theme on windows that
are currently active - i.e., not on background tabs. I’ve not yet figured out
how to fix this - I’ve looked into gnome-terminal’s source
code when I originally wrote the script, and I even
faintly remember reporting this as an issue. Basically that the dbus interface
should be a bit extended. If you know how to fix this, let me know.
Figuring this out took a while. D-Feet has been useful for it.
Generally, it’s very questionable and broke for me at least once (because of
something having to do with which particular knobs are in gconf vs dconf
vs gsettings). Works for me on gnome-terminal 3.44.0. Caveat emptor.
As with the other scripts in here, it’s currently in my ducktape
repo and if I update it later, it’ll be reflected there.
Putting it together
Just make your set_light_theme and set_dark_theme scripts call the
appropriate scripts for gnome-terminal and Neovim. Here’s how they look for
me:
Why is one on PATH and not the other? Tech debt in my personal infra.
Deployment step of built artifacts isn’t separated and my old scripts repo isn’t
yet merged into my maximally glorious Ducktape monorepo. Sue me :P
Still, over time, I’ve made it a project to make the duct tape holding together
my computer have a better CI setup than many commercial software projects :P
Short update
Oh also I’m now in San Francisco and at OpenAI, working on
reinforcement learning. Long time, much news. Also Copilot is
a thing and has surprised me very strongly by how good and useful it is.
Sometime I’ll be writing some sorta summary of last year or two, but today is
not the day and this is not that blogpost.
I’m not doing all that great emotionally, but I’m trying to keep learning RL,
even if slowly. I made Cartpole and Lunar Landing environments work. Both of
them have discrete actions. The next environment I went to try to learn was the
Half Cheetah.
Standing half-cheetah
In this environment, you control a simple robot and are trying to teach it to
run. You control it with continuous signals. I’m not sure what exactly they
mean, probably something like force applied to joints. Continuous actions mean
you need to use slightly different algorithms. I went to learn TD3 (twin delayed
deep deterministic actor-critic), based on OpenAI’s treatment in Spinning Up in
Deep RL. It was
published in a 2018 paper called Addressing Function Approximation Error in
Actor-Critic Methods.
Sidenote: depending on MuJoCo sucks
The vanilla half-cheetah environment is written with MuJoCo. MuJoCo is a
commercial physics simulator used for a lot of robotics environments like
this. You need a license to run it. As of now (October 18, 2021), there is a
free license available for everyone to run MuJoCo until the end of this month.
But in general, closed-source dependencies for open research suck.
There’s this open-source physics engine called Bullet.
I’ve played with it a bit in middle-high school when I was trying to write some
3D stuff. Turns out they have since made Python bindings, and implemented a
bunch of OpenAI Gym environments. So you can now run lots of environments
without MuJoCo :)
To use the PyBullet environments, install the pybullet Python package and
import pybullet_envs. The PyBullet repo has the list of implemented
environments.
Sidenote 2: Actually MuJoCo is now open-source
So, later on the same day I wrote this post, turns out DeepMind bought MuJoCo
and made it open-source and free (at https://mujoco.org/). Good stuff :)
TD3 description
Q learning
To describe TD3 briefly, it’s similar to Q learning.
In Q learning, you’re learning a function \(\hat{\mathrm{Q}}_\theta(s,a)\), and a
policy \(\pi\). You update \(\theta\) to make \(\hat{\mathrm{Q}}_\theta(s,a)\)
match closer to the actual Q function for the policy \(\pi\), and you also
update the policy \(\pi\) to gradually improve. You can do this exactly if
you have a small enough environment to hold all this in memory. The procedure
you use to make \(\hat{\mathrm{Q}}_\theta\) approximate
\(\mathrm{Q}_\pi\) is basically SARSA: you minimize the squared error
between \(\hat{\mathrm{Q}}_\theta(s,a)\) and an estimator that converges to
center on the actual \(\mathrm{Q}_\pi(s,a)\). In the finite case, that
Q learning estimator for a transition \(s \xrightarrow{a} (r, s’)\) is
\(r + \gamma \max_{a’} \hat{\mathrm{Q}}_\theta(s’,a’)\). In vanilla Q
learning, the followed policy is \(\mathrm{greedy}(\hat{\mathrm{Q}})\),
which is what that maximum does.
But when you’re in a continuous action space, you can’t just \(\arg\max\)
over all possible actions.
DDPG
Enter DDPG (Deep Deterministic Policy Gradient), in which you maintain 2
networks: the critic \(\hat{\mathrm{Q}}_\theta(s,a)\) which approximates
the Q value of the current policy, and the actor - a deterministic policy
\(\pi_\varphi: \mathcal{S} \rightarrow \mathcal{A}\), which you improve
based on the critic’s estimations.
Run the agent with your current policy in a replay buffer, plus with some
exploration (like a bit of Gaussian noise added to actions). Draw a batch from
the replay buffer, and do an optimization step on the critic to minimize its
Bellman error:
$$\arg\min_\theta \sum_{(s,a,r,s') \in \mathrm{batch}}
\left[\hat{\mathrm{Q}}_\theta(s,a) - (r + \gamma \hat{\mathrm{Q}}_\theta(s', \pi_\varphi(s')))\right]^2 $$
Then update the actor to choose actions that get better Q values on the same
batch:
$$\arg\max_\varphi \sum_{(s,a) \in \mathrm{batch}} \hat{\mathrm{Q}}_\theta(s,\pi_\varphi(s))$$
The batch has to be drawn randomly. This is important, because if you draw a
bunch of states that immediately follow each other, their predictions will end
up pulling each other to explode towards infinity.
To prevent similar feedback cycles between the actor and critic, you keep 2
copies of each: the optimized one and the target one. They start out as
exact copies. When computing the Bellman targets for the critic, instead of
using the optimized actor and critic, use the target ones:
$$\arg\min_\theta \sum_{(s,a,r,s') \in \mathrm{batch}}
\left[\hat{\mathrm{Q}}_{\theta_\text{opt}}(s,a) - (r + \gamma \hat{\mathrm{Q}}_{\theta_\text{targ}}(s', \pi_{\varphi_\text{targ}}(s')))\right]^2 $$
And slowly Polyak-average
the target networks towards the optimized one (with (\approx 0.05)):
$$
\begin{align*}
\theta_\text{targ} & \gets \varrho \cdot \theta_\text{opt} + (1-\varrho) \cdot \theta_\text{targ} \\
\varphi_\text{targ} & \gets \varrho \cdot \varphi_\text{opt} + (1-\varrho) \cdot \varphi_\text{targ}
\end{align*}
$$
By the way, I made up this a shorthand notation for this operation “update x towards
y with update size (\alpha)”:
$$\require{extpfeil}
\theta_\text{targ} \xmapsto{\varrho} \theta_\text{opt}, \varphi_\text{targ}
\xmapsto{\varrho} \varphi_\text{opt}
$$
TD3
Twin Delayed Deep Deterministic Policy Gradient was introduced in a paper called
Addressing Function Approximation Error in Actor-Critic Methods.
Note the “function approximation error” part. This talks about the error
inherent in how \(\hat{\mathrm{Q}}_\theta\) approximates the real
\(\mathrm{Q}_\pi\). In particular, if in a state \(s\), the critic
overestimates the Q value for some action \(a\), the actor’s optimization
step will be incentivized to exploit that overestimation. But that doesn’t mean
it’ll actually get a better result.
TD3 adds 3 steps to address this:
Target policy smoothing: in the Bellman update, instead of expecting to
follow \(\pi_{\varphi_\text{targ}}\) exactly, add a bit of Gaussian
noise to the chosen action. That way the policy can’t try to hit a small peak
of overestimation by the critic.
Twin critics: train 2 critics, both to minimize the Bellman error. Optimize
the policy to maximize one of them. Instead of setting critics’ targets based
on one critic, choose the target based on the lesser of their two
predictions. If you train 2 networks, they’re unlikely to overestimate the
real Q function in the same place.
$$\arg\min_\theta \sum_{i \in {1, 2}} \sum_{(s,a,r,s') \in \mathrm{batch}}
\left[\hat{\mathrm{Q}}_{\theta_{i, \text{opt}}}(s,a) - (r + \gamma \min_{j\in {1, 2}}\hat{\mathrm{Q}}_{\theta_{j, \text{targ}}}(s', \pi_{\varphi_\text{targ}}(s')))\right]^2 $$
Delayed policy updates: update the policy just once per 2 batches (i.e.,
2x slower than the critics).
Rai’s ML mistake #5: Multiplication? What multiplication?
The following happened over the course of ~6 weeks, as I gathered a few hours at
a time of energy, will, etc. to work on this.
So, I go and implement my algorithm and run it. On my first try, I implement it
wrong because I misremember how to implement it. I go back to Spinning Up in
Deep RL, smack myself on the forehead, and go fix it. Run it again.
It’s learning something. The average reward is going up. But slowly.
Slowly increasing mean reward graph
Then, over the next ~4 weeks, whenever I have some time, I try to bang my head
against the keyboard some more. Tweak all the hyperparameters. Look up the
hyperparameters they use in rl-baselines3-zoo.
No dice. Repeat for a while, for all hyperparameters - critic learning rate,
actor learning rate, actor delay, replay buffer size, batch size, Polyak rate,
discount rate, initial random action steps. Rewrite the code twice-thrice. Still
the same issue. Keep it training for several days. Does not help. Repeat a few
times.
Thanks God there’s a reference implementation
I wanted to implement this algorithm on my own, because I want to grok it.
But I got to the end of my wits here, and started thinking: “hell, can this
algorithm even solve this environment”? The paper had graphs and
results with the half-cheetah. But that was the MuJoCo half-cheetah. Maybe the
PyBullet half-cheetah had a different reward scale and this was actually as good
as it went?
Unlikely. All my half-cheetah did in evaluation was stand upright without moving.
Maybe sometimes kinda jump once.
Standing half-cheetah
But yeah. Let’s run the reference implementation and see what it does. I start
it for a few minutes, and…
...
Total T: 109000 Episode Num: 109 Episode T: 1000 Reward: 938.893
Total T: 110000 Episode Num: 110 Episode T: 1000 Reward: 987.304
---------------------------------------
Evaluation over 10 episodes: 963.088
---------------------------------------
God dammit. I was getting maybe, on a lucky episode, like 300 at most, and
that was after millions of training steps…
Does it just not work because of Tensorflow?!
Okay, so I have code A which does not work (my code), and code B which does
(reference implementation). I know what to do here. Align code A and code B
together so that they’re similar, and then scour the diff line by line.
Somewhere in there there’s my bug.
I refactor my code, rename variables, etc., until the diff is small.
Now the only diff I see is basically me using Tensorflow and the reference
implementation using PyTorch. Stuff like this:
2,3c3,7
< import tensorflow as tf
< from tensorflow.keras import layers as tfkl
---
> import torch
> import torch.nn as nn
> import torch.nn.functional as F
136,137c123,124
< state = tf.expand_dims(state, axis=0)
< return tf.squeeze(self.actor(state), axis=0).numpy()
---
> state = torch.FloatTensor(state.reshape(1, -1)).to(device)
> return self.actor(state).cpu().data.numpy().flatten()
And yet, my code doesn’t work, and their code does.
I bang my head against this for maybe 2 more days. So, where can the differences
be?
Maybe different action scaling. I align action scaling like they do. Instead of
“sigmoid, then rescale from 0 to 1 into action_space.low to
action_space.high”, I do their “tanh, then multiply by
action_space.high”. Those should be basically the same thing, but I do it
anyway just to be safe. Still doesn’t work.
Maybe different initialization. Unlikely, but possible.
Their code uses Torch’s Linear.
It initializes weights and biases both randomly from
\(\text{Uniform}([\pm \sqrt{\frac{1}{\text{input size}} }])\).
I use TensorFlow/Keras’s Dense.
It uses Xavier uniform initialization
(aka Glorot initialization, named … after someone named Xavier Glorot)
by default, which draws from
\(\text{Uniform}([\pm \sqrt{\frac{6}{\text{input size} + \text{output size} } }])\).
And TensorFlow initializes biases to zero.
Okay. I rewrite the TensorFlow initialization to do the same thing as Torch.
Still the same. God dammit.
Does the ADAM optimizer in TensorFlow and PyTorch work differently? … Maybe.
I’m gonna shelve the idea of stepping through it for later.
Copy the whole goddamn setup
I decide that I’ll copy even more of their code. Okay, this is unlikely, but
what if there’s something wrong with how I initialize the environment or
something? I copy their main.py, switch it to TensorFlow, and use their
utils.py.
And now it works, and I scream.
It’s the utils.py that did it. That file in their repo
implements the replay buffer. I didn’t pore over my implementation in detail,
because … hey, it’s the simplest part. How would I mess up a replay buffer?
Their replay buffer exists in RAM, and has NumPy arrays. It uses NumPy’s
randomness. I use TensorFlow variables and TensorFlow’s tf.random.Generator.
After some work, I find the culprit lines.
Here’s how my code stores the replay buffer’s rewards and “is this the final
state” flag:
TD3 maintains 2 critics. critic_target is a Keras model, which contains two
stacks of feed-forward layers. At the end, they have a
q_value = tf.keras.layers.Dense(1, ...), and then the whole model returns the
tuple (q1_value, q2_value).
With that in mind, what’s the shape of target_Q1?
No, it’s not (batch size). It’s (batch size,1). Because
of course there’s the last dimension of size 1 - if your model has more than 1
output node, you need to stack them.
What’s the shape of not_done?
With my replay buffer, it was (batch size). One scalar per experience
in batch, right? With the reference implementation’s replay buffer, it was
(batch size,1).
Consider the line target_Q = reward + not_done * self.discount * target_Q,
where target_Q has shape (batch size,1) and, as established for my
code, not_done has shape (batch size). What’s the shape of the
computed expression?
If you answered (batch size,batch size), I guess you win.
And that was not intended. I wanted it to be (batch size) - one
target Q value for one replay experience in batch.
What happens next with this target_Q?
@tf.functiondef _mse(x, y):return tf.reduce_mean(tf.math.squared_difference(x, y))with tf.GradientTape() as tape:# Get current Q estimates current_Q1, current_Q2 =self.critic((state, action))# Compute critic loss critic_loss = (_mse(current_Q1, target_Q) + _mse(current_Q2, target_Q))# Optimize the criticself.critic_optimizer.minimize( critic_loss, tape=tape, var_list=self.critic.trainable_variables)
… Great. current_Q1 / current_Q2 have shapes (batch size,1),
which is compatible with (batch size,batch size). So they get
auto-broadcast… and reduce_mean gladly reduces the matrix of squared errors
to a scalar mean. Awesome. Thank you. I’m so glad Autobroadcast Man and Default
Options Girl arrived and saved the day.
Learnings
So what did I learn today?
It’s always, always, ALWAYS those goddamn tensor shapes.
And probably write unit tests, too. I probably won’t be bothered to do that
anyway because writing unit tests for code that has complex optimizers and
neural nets is annoying.
And maybe I should be using operators that don’t auto-broadcast, or something
that doesn’t allow me to mistakenly vector-vector-to-matrix multiply when I
mean to vector-vector-elementwise multiply.
I’m not done being annoyed and sour about this but I’m done ranting about it
here. Ciao, see you next time I kill a few weeks on another mistake this stupid.
This is the point of all those “Rai’s ML mistakes” posts. I write these
algorithms so I can grok them, and I headsmash the keyboard this way because
I hope now I’ll remember with a bit more clarity and immediacy: “It’s always the
goddamn tensor shapes”.
My fixed code is on my GitLab, and here’s the obligatory scoot-scoot:
A half-cheetah doing the scoot-scoot after 216 episodes of training.
Update: MuJoCo half-cheetah
So, since MuJoCo is now open-source, I tried it and got the MuJoCo environment
HalfCheetah-v2 also working. Nice :)
Trained MuJoCo half-cheetah. Episode reward is 5330.
Continuing my list of ML mistakes from last
time, here’s:
Rai’s ML mistake #4: Too much autograd
So here I am, writing an agent for
LunarLander-v2.
I’m using Q-learning. I approximate q*(s,a) as
q̂w(s,a) with a neural network, taking a vector representing
the state, and outputting one approximate action value per output.
The neural network is trained to minimize squared TD error on the policy the
agent’s running, which is ε-greedy with respect to
q̂:
$$
\begin{align*}
\require{extpfeil}
\ell(w) &= \mathop{\mathbb{E}}\limits_{(S \xrightarrow{A} R,S') \sim \mathrm{greedy}(\mathrm{\hat{q}}_w)}
\left[ \left(\mathrm{\hat{q}}_w(S, A) - (R + \gamma \max_{A'} \mathrm{\hat{q}}_w(S',A')) \right)^2 \right] \\
\text{output } &\arg\min_w \ell(w)
\end{align*}
$$
Not quite off-policy
One note about the “policity” of this method.
Tabular Q-learning without function approximation is off-policy - you learn
about π* from experience (S→AR,S′) sampled from any
(sane™) policy. You just keep updating q̂(S,A) towards
R + γ ⋅ maxA′q̂(S′,A′), and to max is there because you want
to learn about the optimal policy.
But note that in ℓ(w), the experience (S→AR,S′) is
sampled from the policy greedy(q̂w).
We need to expect over a policy, because we’re using function approximation,
so presumably we cannot learn a w which would make q̂w
exactly fit q*. So we have to pick out battles for how well do we
approximate q* - we care about approximating it closely for
states and actions actually visited by the estimation policy.
Instead of assuming that we can sample (S→AR,S′) from
greedy(q̂w) (so that we can approximate the expected
squared TD error over it), I guess you could use the general importance sampling
recipe to get rid of that:
$$\mathop{\mathbb{E}}_\limits{X\sim \pi}[\mathrm{f}(X)] =
\mathop{\mathbb{E}}_\limits{X\sim b}\left[\mathrm{f}(X) \cdot \frac{\pi(X)}{b(X)}\right]$$
Semi-gradient
So, we want to minimize ℓ.
Note that ℓ depends on w (via q̂w) in 3 places:
In q̂w(S,A), which we are trying to nudge to move to the
right place,
in R + γmaxA′q̂w(S′,A′), which is a sample
from a distribution centered on
qgreedy(q̂w)(S,A),
and in the distribution we’re taking the expectation on.
In practice, we hold (2) and (3) constant, and in one optimization step, we
wiggle w only to move q̂w(S,A) closer to targets.
That means that in our gradient, we are ignoring the dependency of (2) and (3)
on the w that we are optimizing, which makes this not a full gradient method,
but instead a semi-gradient method.
Experience replay
My first shot at this agent just learned from 1 step (sampled from
ε-greedy policy for q̂w) at a time. It worked
in the sense that it ended up learning a policy close enough to “solving the
environment”. (The environment says the “solved reward” is 200. I got maybe like
150-180 over 100 episodes, so not quite there, but it’s close enough for me to
say “meh, I’ll wiggle a few hyperparameters and get there”.)
But to learn a fair policy, it took the agent about 10 000 episodes, and the
per-episode total reward over time made a spiky ugly graph:
I don’t like that it takes all of 10 000 episodes, and I don’t like how spiky
and ugly the chart is.
Experience replay means we store a bunch of experience
(S→AR,S′)1, 2, … in a buffer, and instead of updating
w by some gradient-based optimization method (I used ADAM) to minimize squared
TD error one step at a time, we update it to minimize squared TD error over the
whole buffer, a bunch of steps at a time.
Experience replay should make learning more sample-efficient (so it should need
less than 10 000 episodes). Also, it should reduce one source of “spikiness
and ugliness” in the chart, because the chart will be doing step updates on
a larger batch. Making the batch larger should reduce the variance of the
updates.
Broken code
So, here’s how I initially implemented one step of the update.
self.experience_{prestates, actions, rewards, poststates, done} holds
the experience buffer (S, A, R, S′ respectively for observed transition
S→AR, S′, plus flag to signal end of episode).
@tf.functiondef q_update(self):with tf.GradientTape() as tape:# \max_{A'} \hat{q}(S', A') best_next_action_value = tf.reduce_max(self.q_net(self.experience_poststates), axis=1)# If episode ends after this step, the environment will only give us# one step of reward and nothing more. Otherwise, the value of the next# state S' is best_next_action_value. next_state_value = tf.where(self.experience_done, tf.zeros_like(best_next_action_value), best_next_action_value) targets =self.experience_rewards +self.discount_rate * next_state_value# For all states S_i in the experience buffer, compute Q(S_i, *) for all# actions. next_action_values =self.q_net(self.experience_prestates)# Select Q(S_i, A_i) where A_i corresponds to the recorded experience# S_i --(A_i)--> R_i, S'_i, done_i. indices = tf.stack( (tf.range(self.experience_buffer_size), self.experience_actions), axis=1) values_of_selected_actions = tf.gather_nd(next_action_values, indices) loss = tf.keras.losses.MeanSquaredError()( values_of_selected_actions, targets) grad = tape.gradient(loss, self.q_net.trainable_variables)self.optimizer.apply_gradients(zip(grad, self.q_net.trainable_variables))
What’s wrong here?
The symptom is that the policy is not improving. The total reward per episode
is just oscillating.
The problem
Remember how I said it’s a semi-gradient method?
Here’s the fix:
@tf.functiondef q_update(self):# \max_{A'} \hat{q}(S', A') best_next_action_value = tf.reduce_max(self.q_net(self.experience_poststates), axis=1)# If episode ends after this step, the environment will only give us# one step of reward and nothing more. Otherwise, the value of the next# state S' is best_next_action_value. next_state_value = tf.where(self.experience_done, tf.zeros_like(best_next_action_value), best_next_action_value) targets =self.experience_rewards +self.discount_rate * next_state_valuewith tf.GradientTape() as tape:# For all states S_i in the experience buffer, compute Q(S_i, *) for all# actions. next_action_values =self.q_net(self.experience_prestates)# Select Q(S_i, A_i) where A_i corresponds to the recorded experience# S_i --(A_i)--> R_i, S'_i, done_i. indices = tf.stack( (tf.range(self.experience_buffer_size), self.experience_actions), axis=1) values_of_selected_actions = tf.gather_nd(next_action_values, indices) loss = tf.keras.losses.MeanSquaredError()( values_of_selected_actions, targets) grad = tape.gradient(loss, self.q_net.trainable_variables)self.optimizer.apply_gradients(zip(grad, self.q_net.trainable_variables))
So, what was the problem?
The code calls the Q network twice: once to compute the targets (R + γ ⋅ maxA′q̂w(S′,A′)), once to compute
q̂w(S,A). Then, we will compute a loss, and we will take its
partial “semi-derivative” with respect to w, and apply the gradient to
bring q̂w(S,A) closer to the target.
The problem was: I also put the target computation into GradientTape scope,
so the optimization was given the freedom to change not just
q̂w(S,A), but alsoq̂w(S′,A′).
So the fix was just to move computing the targets out of the GradientTape
scope.
I looked at this code basically non-stop for 2 hours, and I realized the error
when I took a break and talked with a friend.
Pet peeve #47: math typesetting
The full list of previous 46 pet peeves will be provided on request, subject
to a reasonable processing fee.
MathJax, \hat and \mathrm
q̂ is a function (of w, S, A), not a variable, so it
shouldn’t be typeset in italic. I tried using \hat{\mathrm{q}}_w. I believe
that works in LaTeX but turns out that MathJax is not willing to render it
($\hat{\mathrm{q}}$). But \mathrm{\hat{q}} is perfectly fine:
q̂. But \mathrm{\hat{q}}_w is perfectly fine:
q̂w.
MathJax and inline \xrightarrow
Also, my MathJax doesn’t seem to understand \xrightarrow in inline equations.
That’s a shame, because S \xrightarrow{A} R, S' is more readable than
S \rightarrow_A R, S' (S→AR, S′), which I used here instead
(in inline equations). It looks like this:
$$S \xrightarrow{A} R, S'$$
Let me know if you know what’s up with those MathJax things.
I wonder if it’s MathJax being wrong, or me sucking at LaTeX.
Why I’m a math typesetting snob
Typesetting things that aren’t variables as if they were variables really bugs
me, because it makes the formulas really ugly. And the font you use to typeset
a math thing is a very useful hint for the reader about what sort of object it
is. I learned a bit about it when volunteering as a
KSP organizer - KSP is full of math snobs. Compare:
$$
\begin{align*}
\mathrm{Loss}(w) = \sum_i (\mathrm{f}(x_i) - y_i)^2 \\
Loss(w) = \sum_i (f(x_i) - y_i)^2
\end{align*}$$
In the second one, it takes a bit of processing to understand that Loss is
not a multiplication (L ⋅ o ⋅ s ⋅ s), and that f(xi) is
function application.
If you want to read more, you can take a look at Typographical conventions in mathematical
formulae on Wikipedia.
Or maybe some LaTeX / TeX books or reference material might have a lot of
explanations, like “use this in these situations”. And also good math books
often have a large table at the front which explains used conventions, like
“w is a vector, X is a matrix, f is a function,
…”
https://xkcd.com/1015/
Now you know about ugly errors in math typesetting, and if you Google it,
also about bad kerning. You’re welcome, pass it along.
Recently I’ve been working on skilling up on reinforcement learning,
particularly practice. I’m currently on the last course of the
Reinforcement Learning specialization
from University of Alberta on Coursera. The last piece of the course is about
solving the Lunar Lander
environment. I’ve been trying to solve it on my own first before going through
the labs, so that I can learn things deeper and experiment.
I’ve tried implementing an actor-critic agent. The actor is a feed-forward
neural network specifying a parameterized policy πθ. The network’s
input is a representation of the state, and it has one output per action.
The policy is a softmax over these outputs. I tried a critic for predicting
both v̂w, and q̂w.
I’ve not had good luck getting this to work so far. At one point I got the agent
to fly above the surface (without landing), but then later I edited the code
somewhat, aaaaand it was gone.
I stared a bunch into my update equations, but have not been able to find any
obvious errors. I used TensorFlow’s
HParams
to try to tune all the hyperparameters, like actor learning rate, critic
learning rate, and learning rate for the average reward. (I wrote it attempting
to use the continuing average reward formulation.)
I decided to first try a simpler environment, CartPole.
In the end, I managed to solve it a couple hours back.
In the implementation, I’ve made a couple mistakes and observations, which I
want to note down.
Colab notebook with my CartPole agent
Here’s my notebook if you want to play around:
Rai’s ML mistake #1: Short episodic environments can use high γ
I initially wrote my code to use a discount rate of 0.9. On
n1try’s solution
that I found on the leaderboard
(unfortunately not sure which one it was), the discount rate was actually set
to 1.
I suspect I might have set the discount rate too low. The CartPole environment
has episodes which have length of only up to ~500, with 1 unit of reward per
step.
If you have a discount rate γ and an average per-step reward of r,
then in an infinite environment, the value of a state will be something like:
$$ \frac{r}{1-\gamma} = r + r \cdot \gamma + r \cdot \gamma^2 $$
Knowing this, I was a worried that if I set γ too high, the targets
for the Q network to learn would have a high variance. But I forgot that the
environment had only like ~500 steps, so setting γ = 1 would be alright
in this case.
Lesson learned: I need to keep in mind the environment’s characteristics, in
particular how long are the episodes and how high total rewards can I expect.
Rai’s ML mistake #2: Too little exploration
The algorithm that ended up working for me was Q-learning (with function
approximation by a small neural network). I selected actions
ε-greedily, with ε set to 0.02, so ~2% chance of
random moves.
Looking at some solutions of the environment that I found, they had much higher
exploration rates. Some that I saw had 100% random actions initially, and had
it then decay. And the particular solution I was looking at set the minimal
exploration rate, after all the decay, to 10% - 5x more than I had.
I think my code found a policy that “solves” the environment faster when I put
in 10% exploration.
Rai’s ML mistake #3: Evaluation interfering with training
I ran my algorithm on 10k episodes, and every 1k episodes, I ran the code in
“greedy mode” (i.e., no random actions) and recorded average performance on 100
episodes. I did that because my Q-learning implementation was executing an
ε-soft policy, which might be worse than the greedy policy that
it’s learning. I don’t know how “fragile” the CartPole environment is (i.e.,
how much worse the total reward per episode gets if I force an agent to take
some amount of random actions), but I wanted to rule it out as a source of
errors.
I implemented the evaluation by just adding a flag train: bool = True to
the agent’s functions. If train was False, I’d skip all the update steps
and select actions greedily.
Unfortunately, I ended up making a mistake and I forgot to add the condition
around one branch of code - updating the Q network after a final step (i.e.,
when the agent receives a last reward and the episode ends).
As a result, the agent ended up executing ~100 incorrect updates (based on
an incorrect last action and state, towards the final reward), one incorrect
update per evaluation episode.
Lesson learned: Double check my code? Maybe even test my code? Not sure
how to learn from this :/
So, until episode maybe 400 or so, nothing much is happening.
Then until about step 1800, it’s sorta doing something but could be better.
Then at around step 1800, it finds a good policy, and returns are nice.
Basically, problem solved.
Then I train it for a bit longer, and at episode ~2.2k… for some reason
performance goes WAY down for about 300 or so episodes. It’s as bad as if the
network forgot everything it learned before.
Then, after a while (at about 2700), it quickly climbs back up to good
performance. On the full graph with 10k episodes, this cycle would repeat maybe
every 2000-3000 episodes. Wat.
I have no idea what’s going on here. Maybe one sort-of ideas, but I have not
tested it, and I have a relatively low degree of confidence in it.
Maybe for some reason the critic might overfit in some way that makes it behave
badly on some early action. Maybe it’s trying to learn some relatively “late
game” stuff, and the update that happens ends up screwing some early behavior,
so the agent then has to spend a bunch of episodes learning the right early
behavior again. The policy changes in a non-continuous way, so if some early
decision switches to do the wrong thing, the agent will then have to follow a
bunch of wrong trajectories until the one-step Q updates end up bubbling up to
the initial wrong decision. I guess this might be somewhat mitigated by using
eligibility traces so that updates bubble up faster, or by using actor-critic
with soft policies.
Another potential reason for having a really bad episode might be if the agent
happens to pick a random action (with probability ε) at an early
point where the pole is unstable and very easy to mess up. And then it can’t
recover from that error. But that explanation isn’t supported by how wide these
areas of low episode returns are. It might explain maybe one sporadic bad
episode, but not a whole bunch of them after each other.
Next steps
Now that I got a CartPole agent running, I’ll come back to the Lunar Lander
environment. I’ll first try solving it again with a Q network. I could probably
similarly get away with not discounting rewards at all (γ = 1).
Also I’d like to implement experience replay to make this more sample-efficient.
If that ends up working, I still want to get actor-critic working.
The last about 2 weeks I have taken some time to finally get practical AI experience, so I’m running TensorFlow and all, and making lots of Anki cards.
Sidenote: Anki for programming is awesome!
By the way, Anki cards are so useful for learning how to use libraries fluently without looking things up it’s ridiculous.
For example, thanks to a bunch of Clozes, if you give me a CSV dataset, I can define, train and evaluate a network using the Keras functional API, without looking up anything. It means I get quickly to the interesting stuff, and don’t waste 80% of my time looking up things I already looked up before. If I see that I’m looking something up for, say, the 3rd time, I just make the cards that would have helped me, and that might be the last time I look that up.
Can a computer now write similarly well to me?
I saw very interesting examples of how well modern language model can generate text, and I’m wondering how close can I be emulated at this point. Depending on how good a language model is, it could replace the copywriting industry and make a 1000% profit margin on top. And I sort of wonder how close it is to me. Though I’m not sure what would I do if I learned my writing can be replaced. I guess I would continue enjoying it, because it feels like I’m “expressing my soul”, and also it’s useful to sharpen my thoughts. If my understanding of something is foggy, when I write things down, I can much more easily spot where exactly I’m confused, or what’s a question I can’t answer, or to realize “hey actually I made a logical error, I no longer believe the conclusion I wanted to justify”.
But I guess I could then just as well automate this whole website thing. I put too little stuff on it anyway - if I just got myself to do the work and put my ideas into polished-ish writing, I would write so much more.
I guess I’d still write also because there’s some pleasure in someone telling me “oh by the way I read your article the other day, thanks for that tip”. And I’d not get that from text I had a Transformer write. Even if it did manage to write a thing as good as me or better, so that people would compliment me for “hey nice thing on your website”, it would still make me go a bit “nice!”, but it would ring a little hollow, I guess. Praise for work that isn’t mine. But then, did the Transformer really “work” for it? Also the work coming up with the architecture and implementing it and making Write With Transformer belongs to many many other people.
Experiment
So I’m going to try it in this article. I will start slowly replacing words by top suggestions (Write With Transformer distil-gpt2). I’ll start with maybe 90% me, 10% Transformer, and by the time I finish writing this, it’ll be 100% Transformer. And I won’t, at least for now, tell you which parts are me and which are the generator. That way I won’t have just a test of “I can / cannot be replaced by a Transformer”, but by asking people which sentences were from me and which were from the Transformer, I’ll get more gradual information about the point at which today’s Transformers can replace me. From what I read, models like GPT-3 are able to convincingly copy “surface style”, and they are able to make simple inferences, but they might make mistakes.
By the way, the footer of Write With Transformer says: “It is to writing what calculators are to calculus.” And that’s a nice sentence in that, on a shallow reading, it sounds like a positive comparison. “It is to writing what [things for doing mathematics] are to [field of mathematics].” But I never had a calculator that was any good for calculus. I never saw a calculator with a “derive by x” or “indefinite integral dx”. Though now I also wonder why no calculator has it. It would be so useful, and not that hard to implement. Mathematica can integrate most of what you throw at it! And algorithms for integrating broad classes of functions are also totally a thing in literature!
“It is to writing what Mathematica is to calculus”? Sure. That sounds useful. A
tool that can solve 90% of practical problems. Neat. “It is to writing what
calculators are to calculus”? AAA, you know what? I’ve been
in many situations where you can have all the calculators you want, and they won’t save you from an ugly enough integral.
It sounds like one of those “proverb insults”, like “you must be at the top of the Gauss curve”.
Also the test of making the Transformer generate parts of the article can show
if it could be useful as a computer-assisted authoring tool.
I wonder what a problem is there with making the
jobs of some people much easier with AI like this. For example, I have a virtual assistant, and I think it should be possible to augment them with a Transformer. You train the Transformer on chats of the highest rated virtual assistants with customers, and annotate the conversations with times when the virtual assistant had to do something. Then you integrate that Transformer into, say, Google Chat, and add some quick shortcuts, like “Tab” for “autocomplete”. I fully expect we should be able to mostly automate conversation like “hello, I hope you’re having a nice day”.
Motivation to do my own thing
By the way, the other day I stumbled on Better Explained, and the author has a great article: Surviving (and thriving) on your own: Know Thyself.
And this is the best of sources of motivation to do my own thing that I’ve
seen in a while. This article made me realize that yes, there are actually things I want to do. I can just look at my TODO list in my Roam Research database. If I only had the most productive ~8 hours of my time available for all the things I want to learn and make.
So I’ve been considering going part-time at Google. For some time I’ve found
that I just can’t muster the energy to be consistently productive after work. And switching contexts is expensive, and gets much more expensive when you switch to a context you haven’t seen for a couple days. Like what might happen if one day I do 4 hours of Colab experimentation, then the next week I don’t have spare energy after work, and then a week later I open the notebook again, read and go 🤨. It helps to keep notes, and not half-ass the code style too badly, but there’s a trade-off between “help future-me quickly get back to productivity on this task” and “spend energy making progress”.
Also, with stocks having recovered from COVID and with Bitcoin currently going through Another One Of Those, I’ve been closely watching how much longer until financial independence.
I am not at the point of “I’ll be able to live on this on my current standard
forever”. But at a lower standard? Like moving back to Czech Republic? For some
values of “lower standard”, yes. And at some some point, the marginal expected
gains from a higher monthly budget will become dominated by the gains of having
more free time. And that makes it less and less rational to trade financial security for freedom.
And it’s not like I can’t make money doing things I want to do, either. There’s
such a huge spectrum. I can career-steer at Google more boldly, or go part-time
to do my own thing. Or even if it’s a little less expensive It might not be just the same freedom as reducing my hours, or working with a company that’s more closely aligned with my interests, or even quitting and doing my thing.
Still experimenting
By the way, I’m still doing the GPT-3 of this article thing, with slowly
increasing density. And as I increase the density, I expect it will be more
“efficient” to just output tons of filler text. Filler is used in more
articles than crisp sentences that have only narrow meaning. If GPT-3 outputs
“What gives?” after any of my sentences, it will probably get a higher reward
than if it outputs “an endomorphism that is an isomorphism is an automorphism”,
just because it’s all too hard to get some extra filler into a place where it would not plausibly fit. What gives?
So expect this piece of writing to slowly degrade from saying something to
saying nothing in so many words. And I’m doing it in my mind expecting
some successive Tab press to generate either nonsense, or bullshit. I m
going to continue to keep it in line with making sense, as far as I’m able to express myself through filler text.
As a result, I think this will sometimes end up stating things I don’t
actually endorse or believe. If that happens, I think I’ll also release the
“spoiler” (annotating the sections of this text that are generated) immediately,
so that I don’t accidentally say something like “I for one welcome our AI
overlords”. Well, I am sure I will As long as we as a species don’t fail the exam.
As far as I’m concerned, I will continue to put together articles on
whatever interests me, to write code for problems I want solved, and to try to
improve my habits.
If the worldview and “values-view” and “lifestyle” that I want to implement
sticks, then the same can be said for every positive change it’s brought
the past couple weeks. So, what’s really causing this to slip away slowly?
Why have previous times when I held similar viewpoints slipped back into
routine? Maybe it’s just because it’s been the default for so long for me to
work through the things I like Slowly, slowly because of all the panic from ideas like “maybe I might have to leave work or start burning money instead of making it”.
And that will change with time Or so would I hope. Advertisements
Popular media. I will be keeping track of all those attention-eaters. I don’t want to have a week where all my energy goes into a black hole.
I just want to keep going.I don’t want to get bored.
Curiosity and learning things and solving problems for people is life.
I just want to have something that will change andchange and improve my
life. In the direction of more aliveness and generating meaning.
And to keep doing that I can only have one way or another
The bottom line is I don’t want to do things I want to do in the way that I
want to do. Not with the current default setting where “want” tends to fall back.
I want to do everything that I can to get my attention. But not with the
current default setting where “want” tends to fall back. I don’t want to get
bored. It’s just a matter of how much I like it. In the moment.
And for those of you out there who are interested in reading, please, like me, subscribe to my Facebook page and share your thoughts about the situation with me . (By email or to your friends , subscribe to my blog here.) I will be taking the time and effort I have put into writing to make it easier to make things better for you.
And for those of you who aren’t interested in reading, please , like me, subscribe to my Facebook page and share your thoughts about the situation with me. (By email or to your friends, subscribe to my blog here.) I will be taking the time and effort I have put into writing to make it easier to make things better for you.
So I’m going to be publishing the article in the second week and I’ll be
posting the article in the second week and I ’ll be posting the article in the
second week and I’ll be posting the article in the second week and I am
posting the article in the second week and I will be posting the rest of
the post and I will be posting to RSS and Atom and Hacker News maybe and
maybe on the same page. If you like the content you see in this website,
thanks, I really appreciate you! You know the best way to make your next book
available is to check out my Blog
I might be repeating the experiment with different language models, to see which ones can keep going to a higher density without devolving into meaninglessness.
But if you do it this way, and have more questions, I’ll post it again, and I
’ll be posting it guess in which week. From what I gather from this experiment, looks like I might not be 100% obsolete just yet. Walk on warm sands.
TL;DR: Principle of no non-Apologies: “Distinguish between saying I’m sorry
and apologizing. Don’t give non-Apologies.” Do not Apologize when you don’t
agree that you fucked up. When you fucked up, own the fuck-up and, if it’s
systematic, commit to reducing future fuck-ups.
Everyday “I’m sorry” is usually not an Apology
“I’m sorry” can be used in several ways.
One way is using it as a conciliatory gesture, basically saying “you’re stronger
than me, I submit, please don’t hurt me”. It’s one possible way I might react
when under threat by someone stronger making demands I don’t agree with.
Another way is to say “this was accidental, I didn’t intend to hurt you”, like
when you bump into someone when boarding your tram.
But when you use the words that way, you are not making an Apology. And it’s
useful to distinguish between these uses of “I’m sorry” andactual Apologies.
Apologies and non-Apologies
Courtesy of an unknown source that I can’t immediately recall, you are
Apologizing when you:
Communicate understanding that you behaved badly (and own responsibility for
it),
try to fix the negative consequences of that behavior, and
commit to work on not acting similarly in the future.
An Apology which holds to this definition makes you vulnerable (because you are
open about the weakness that caused the behavior), and it’s not to be made
lightly, because of the commitment. It is also virtuous to own your mistakes or
systematic problems, and to work on them.
On the other hand, if you use the ritual apologetic words but do not meet these criteria, let’s call that a
non-Apology.
A prototypical example is “I’m sorry you feel that way”, which happens when a
sociopath in charge is forced by overwhelming force to “Apologize”.
“I’m sorry” that you tell your boss just to make them stop grilling you is also,
under my use of the word, a non-Apology.
So is, in many (but not all) cases, a “sorry I’m late” I might say when coming
to a meeting. Also the “bump into someone on the tram” example, and the “I yield
I’ll do what you demand” example.
(So, notice that I’m not saying non-Apologizes are morally bad. Some of them
are, but many are also just those tiny social rituals you need to do so you
make it clear to people you aren’t a dick.)
Principle of no non-Apologies
My principle of no non-Apologies is two-part:
Distinguish between saying “I’m sorry” and Apologizing.
This first part I recommend adopting universally. Know the difference between
the social ritual that evolved from small routinized Apologies and actual
Apologies, and know which one you are doing at which time.
Don’t give non-Apologies.
This second part I apply to relationships into which I want to bring my whole
self, mostly my personal relationships, but also some work relationships.
Unfortunately, many of us are stuck in power differential relationships with
people who demand apologetic-sounding words, and there might be no better
solution than to yield. But still, it’s good to know that you are saying “I’m
sorry”, and not Apologizing. That way, you can appease without cognitive
dissonance.
But in relationships with mutual care and respect and compassion, it should make
sense that you shouldn’t be obliged to Apologize if you don’t agree that you did
anything wrong. When you feel pressed to apologize, your first instinct should
be to ask what you did wrong, and if there are different viewpoints, have a
conversation.
If your behavior is worthy of an apology, don’t stop at “I’m sorry”. Understand
why the behavior happened, and work to prevent it from causing more bad
consequences in the future.
P.S.: Generalizations
This is just one instance of a more general move of looking at some social
ritual (like apologizing) and looking at it a little “sideways”: getting back
in touch with the original meanings of the expressions used in it. Rituals and
words can lose meaning over time, and you can lose concepts when that happens.
If you want to see what it’s like to look at things that way, I’ve had a pretty
vivid experience of it after finishing Wittgenstein’s Tractatus.
TLDR: Fixed mindset and fear of inadequacy hinder learning. Competence gives
you confidence - where you’re competent and confident, you don’t have fear of
inadequacy. And if you don’t learn fast because you’re afraid of feedback
(because you’re afraid of inadequacy), you’ll not get better, leaving you
relatively incompetent and afraid of inadequacy. 🗘
A thing about sex recently clicked from several sources:
Being high and talking with a certain sergal,
plus reading a Facebook thing by Duncan:
plus listening to John Vervaecke’s series Awakening from the Meaning Crisis.
(One of the episodes talks about fixed/growth mindset, but I can’t find it
right now. You should go watch the whole series anyway, it’s awesome.)
During sex, I have a background fear of “what if I can’t bring them to orgasm”.
I want my partner to enjoy it as well, and I want to reciprocate, and I would
feel bad if they bring me to orgasm but I can’t bring them to orgasm. So, I
hurry and try hard to bring them to orgasm, because I am not confident of my
sexual skill. Orgasm is cool, but the sex before orgasm is also cool. Sex that
doesn’t feel hurried and where you can take your time and stretch out pleasure.
But, so far, in like 90% of the sex I’ve had so far I had the thought “aaaa sex
aaaa gotta perform and be good enough and hurry and give them an orgasm aaaa”,
somewhere in the background. In that kind of environment, you don’t get a lot
of learning done.
Say you’re learning how to play the violin. We know lots about learning. CFAR’s
handbook (which I think is still not publicly readable) has a lot of useful
stuff on it. Things that make learning work well include:
You need to learn the basics first. You don’t start by playing Vivaldi’s
Four Seasons. You start by playing one note until you get that one note at
least 90% right: holding the violin correctly, not having the bow screech, not
touching the strings that shouldn’t ring, holding the tone for as long as
required without it fluctuating (unless you want it to).
You need feedback, and the faster the feedback loop is, the better. If you
play the Four Seasons and by
Summer you start holding the bow wrong, your violin tutor will immediately
stop you and tell you. The tutor won’t wait the remaining 20 minutes to tell
you that starting with Summer they stopped enjoying your performance and just
hoped you’d get it over with soon.
So. When having sex, I hurry because I worry I might be unable bring my partner
to orgasm, making the experience less than optimal. And I never really get
learning done because I always hurry because I worry I can’t bring my partner to
orgasm, which I worry about because I never learned enough to be confident in my
ability to do that. 🗘
With the next couple of partners I have, I think I’ll ask if we could get some
learning done. As in, play the Four Seasons, and tell each other if we’re off
tune or in the wrong rhytm or need to tune the strings. And ask proactively,
too. If you’re scared that holding the violin wrong makes you a not-good-enough
violin player forever, you’ll be holding it wrong until you chance upon the
right way by stochastic gradient descent, with the loss function being “the
partner’s body language looks happy”. That also converges (if you’re good
at reading people), but slower.
Go learn about growth/fixed mindset if you haven’t yet.
I’ve known about the concept for a while, but somehow I never thought of
applying it to this area until now. And I suspect a lot of the places where I’m
not competent right now are also places where I have fixed mindset but haven’t
yet realized it or addressed it. Peace.





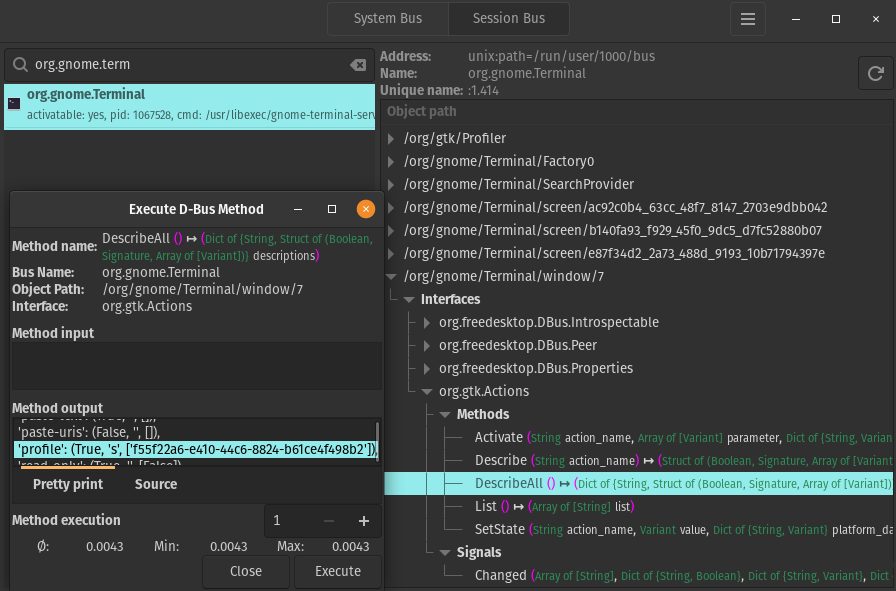


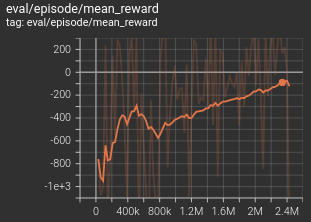


_ <-- ded")
")
